![]()
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
使用线程可以把占据长时间的程序中的任务放到后台去处理。
用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
程序的运行速度可能加快
在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
Python 提供了多个模块来支持多线程编程,包括 thread、threading 和 Queue 模块等。程序是可以使用 thread 和 threading 模块来创建与管理线程。 thread 模块提供了基本的线程和锁定支持;而 threading 模块提供了更高级别、功能更全面的线程管理。推荐使用更高级别的 threading 模块,而不使用 thread 模块有很多原因:threading 模块更加先进,有更好的线程支持,并且 thread 模块中的一些属性会和 threading 模块有冲突,另一个原因是低级别的 thread 模块拥有的同步原语很少(实际上只有一个),而 threading 模块有很多。再有避免使用 thread 模块的原因是它对于进程何时退出没有控制。当主线程结束时,所有其他线程也都强制结束,不会发出警告或者进行适当的清理。如上所述,至少 threading 模块能够确保重要的子线程在进程退出前结束。
下面会使用传统单线程和多线程进行网页爬虫。
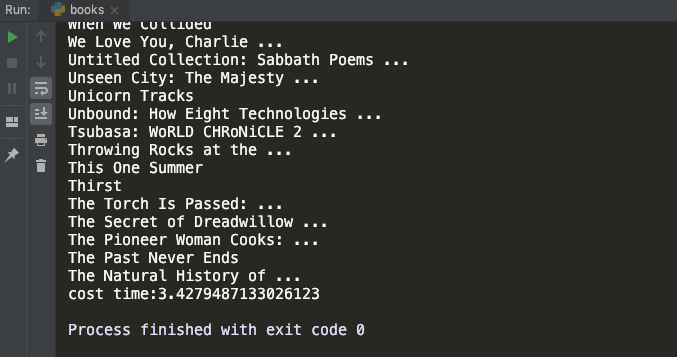
单线程爬虫
1 | import requests |
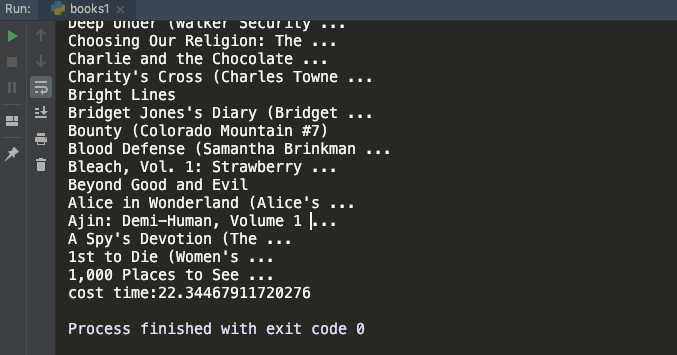
多线程爬虫
1 | import requests |