![]()
京东网站是我经常去购物的网站,现在来爬京东商品的评论。有时候网速慢,打开评论的时候还要等一会,一直在加载,也证明了其评论是网页动态加载的。
而去爬取动态加载的网页,无非就是查看其 js 请求和使用 selenium 工具,这里使用了前者的方法,比较简单。
查看动态 js 请求
先打开开发者工具,然后再打开京东商品 iPhone X 评论页面,可以看到,请求列表中有一个 productPageComments 文件,打开它,点击 Preview 标签,下面的数据是 json 形式,再点击 Comments ,查看其中正是需要的评论数据。
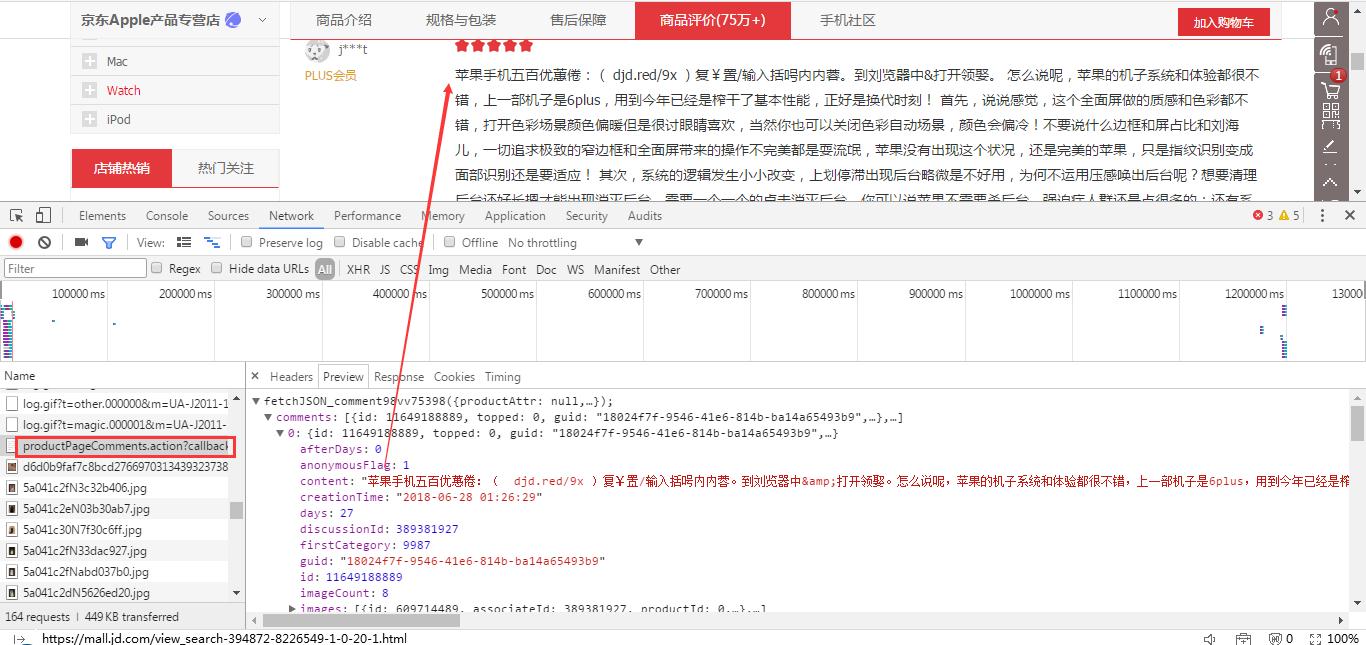
对 js 文件进行请求
1 | import requests |
在这段代码中,先查看对 js 文件网址请求之后,得到的数据是什么。
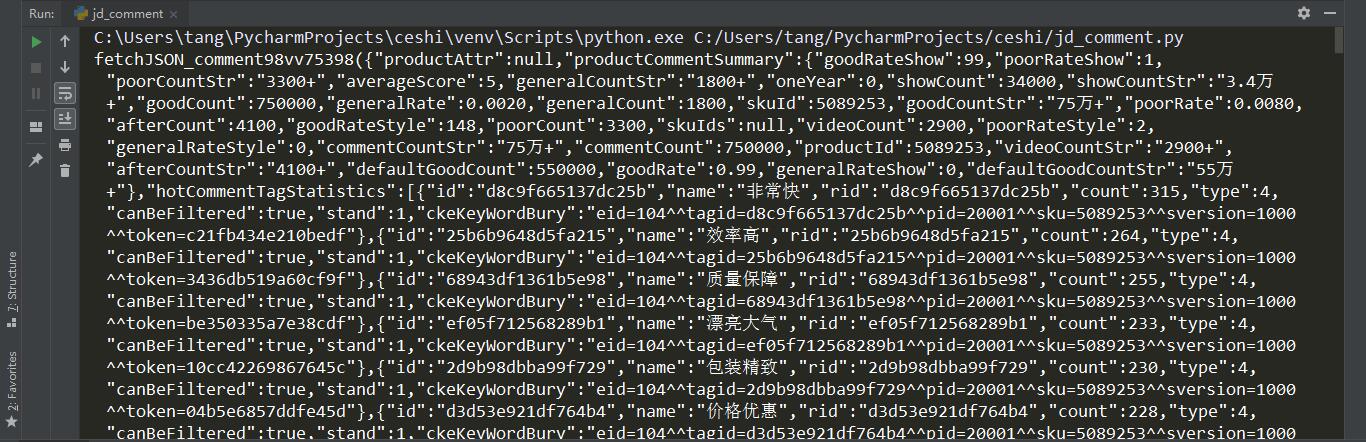
输出的数据为 json 形式,但是数据首尾都有一些多余数据,为了把它变成正常的 json 形式,我们用 replace 方法替换掉多余部分。
1 | result = response.replace('fetchJSON_comment98vv75398(', '') |
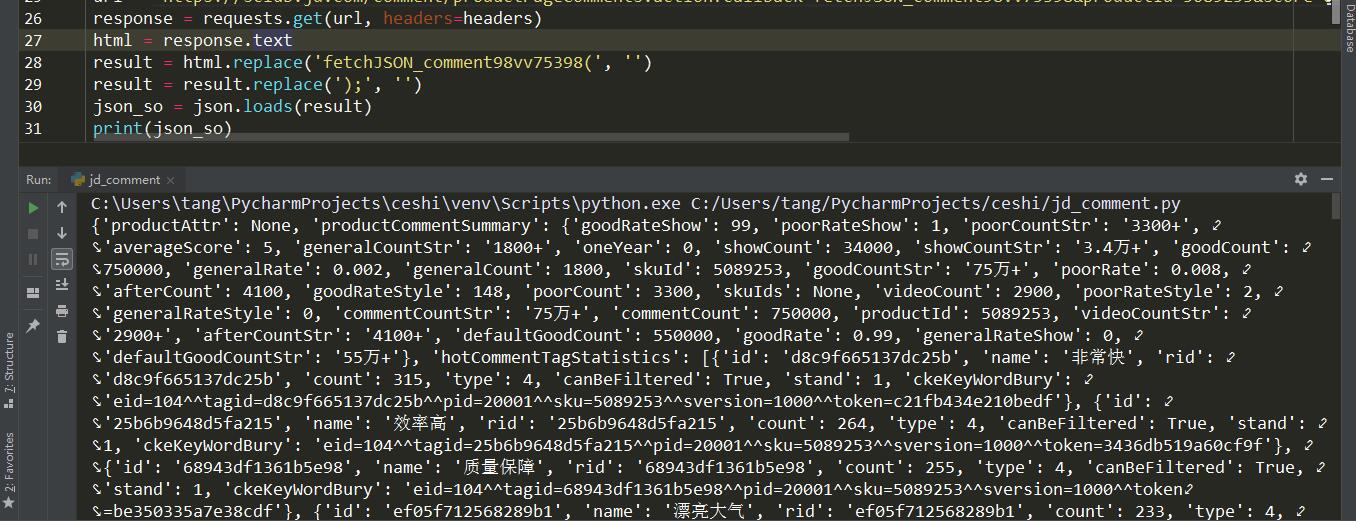
这样我们输出的数据就是正常的 json 格式,可以进行提取信息的操作了。
提取数据并构造翻页网址
把上一步输出的数据放入 json在线解析 网页中进行解析,得到如下图。

证明我们上一步操作没问题,接下来提取数据。1
2
3
4
5
6
7
8items = json_so.get('comments')
for item in items:
id = item.get('id')
content = item.get('content')
create_time = item.get('creationTime')
nick_name = item.get('nickname')
client = item.get('userClientShow')
print(id, nick_name, content, create_time, client)
这样就可以得到商品评论的 id, 内容,评论时间,评论人昵称和评论人客户端信息,如下图。
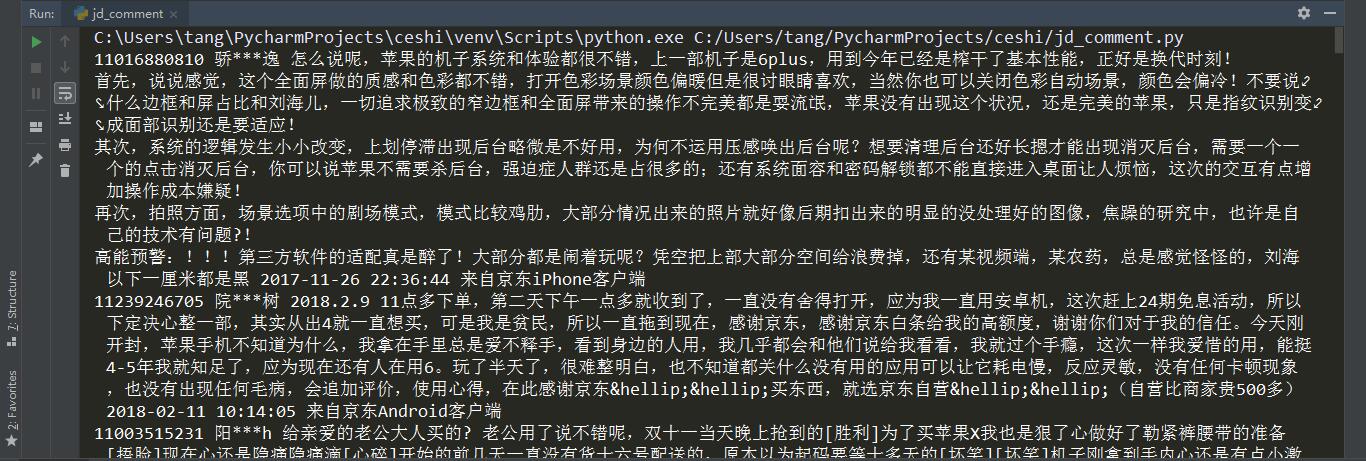
接下来要构造翻页网址,通过观察每一评论页网址,发现其参数中有个 page 参数,这个是页码参数,所以我们只要对 url 中传入不同的 page 值,就可以进行翻页。1
2for page in range(10):
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv75398&productId=5089253&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1'
整理数据
最后把评论信息都写入文件中,如下图。
保存至本地文本文件

保存至MongoDB数据库

完整代码
1 | import requests |