![]()
最近学习了 scrapy ,之前刚开始爬虫的时候有接触过这个框架,当时看了下工作原理有点难懂,现在慢慢地接触爬虫多了,回过头来开始了解爬虫框架,现在再来看它的工作流程就明白了很多。
本篇文章使用 scrapy 来爬取简书全站文章。
scrapy 工程创建与配置步骤(个人习惯):
- 创建 scrapy 工程,创建启动文件 start.py ,修改 settings.py 配置文件
- 进入 spider.py 文件开始写爬虫规则
- item.py 中设置存储模板
- 写 pipeline 存入数据库
创建 scrapy 工程
windows 系统在 scrapy 工程文件根目录:打开命令行工具,输入命令创建工程。1
$ scrapy startproject [工程名字]
cd 到工程文件夹下,创建爬虫文件,默认使用 basic 模板,同样在命令行中。输入1
$ scrapy genspider [爬虫名字] [爬虫网址]
这样就完成了一个 scrapy 工程的创建。但是这里爬取简书全站我使用的是 crawlspider 爬虫,其有可编写的爬虫规则,使用起来比较方便。
为了方便启动工程,我都会在创建好 scrapy 后再来创建一个启动文件 start.py 。
修改 settings.py 文件,将其中的遵守 robots.txt 协议关闭,开启 headers 其它配置等需要的时候再去更改。
进入 spider.py 写爬虫规则
这次爬取的是简书全站的文章,因此要找所有文章的链接规则,每篇文章阅读到最底部,简书会推荐给我们一些其它文章,几乎每篇文章下面都会有推荐,因此我们从这里入手,查看了源代码,发现了它们的链接形式都大致相同,https://www.jianshu.com/p/7a4879ef6f8d ,https://www.jianshu.com/p/cde1742518c8 ,如图。
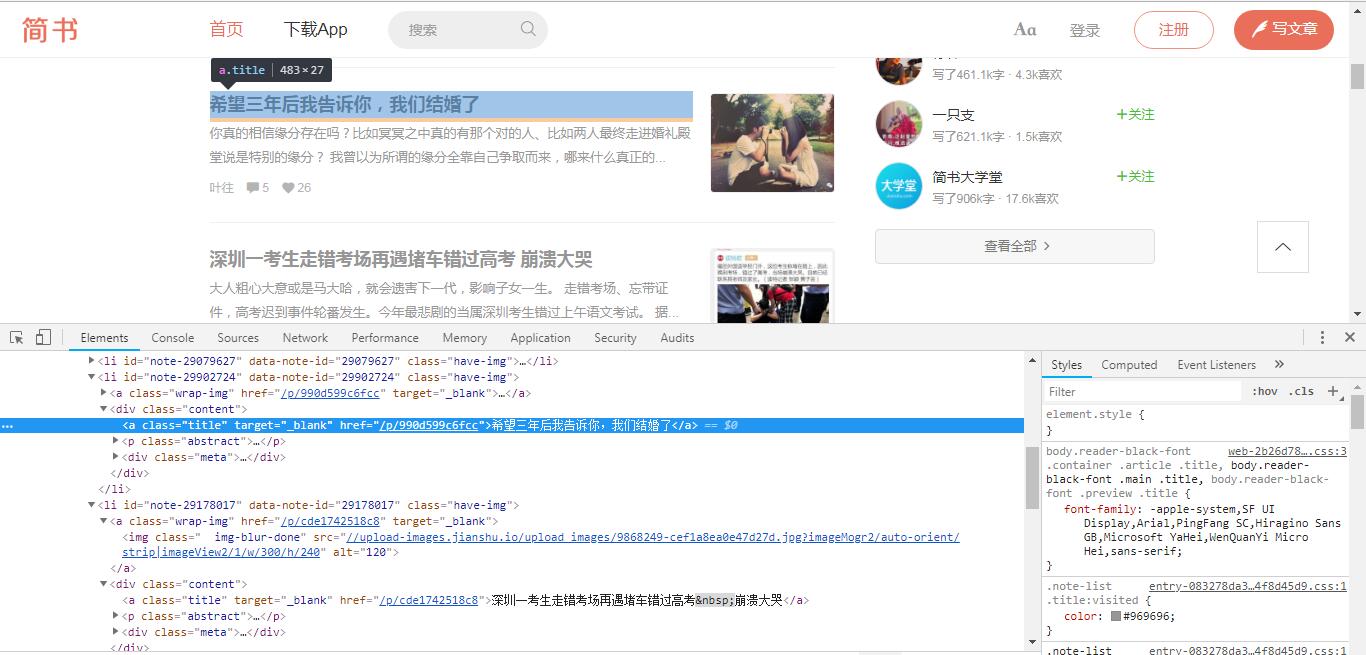
可以看到,都是 p 后面接上一大串数字字母的混合字符串,因此可以写出它的规则,使用正则表达式,如下。1
2
3rules = (
Rule(LinkExtractor(allow=r'.+/p/[a-z0-9].+'), callback='parse_detail', follow=True),
)
rules 是一个元组,其中,Rule 写的是爬虫的规则;callback 指的是回调函数,也就是当获取到了前面取到的 url 之后,程序该去调用哪一个函数的操作,而这里就是去调用 parse_detail 这个函数; follow 表示跟进,如果其 ==True 表示要继续跟进,也就是我们进入一片文章之后,要继续跟进下一篇文章。
在进入一篇文章之后,我们要获取到它的标题,发布者,发布时间,还有内容这四个部分。这里使用 xpath 方法来获取。
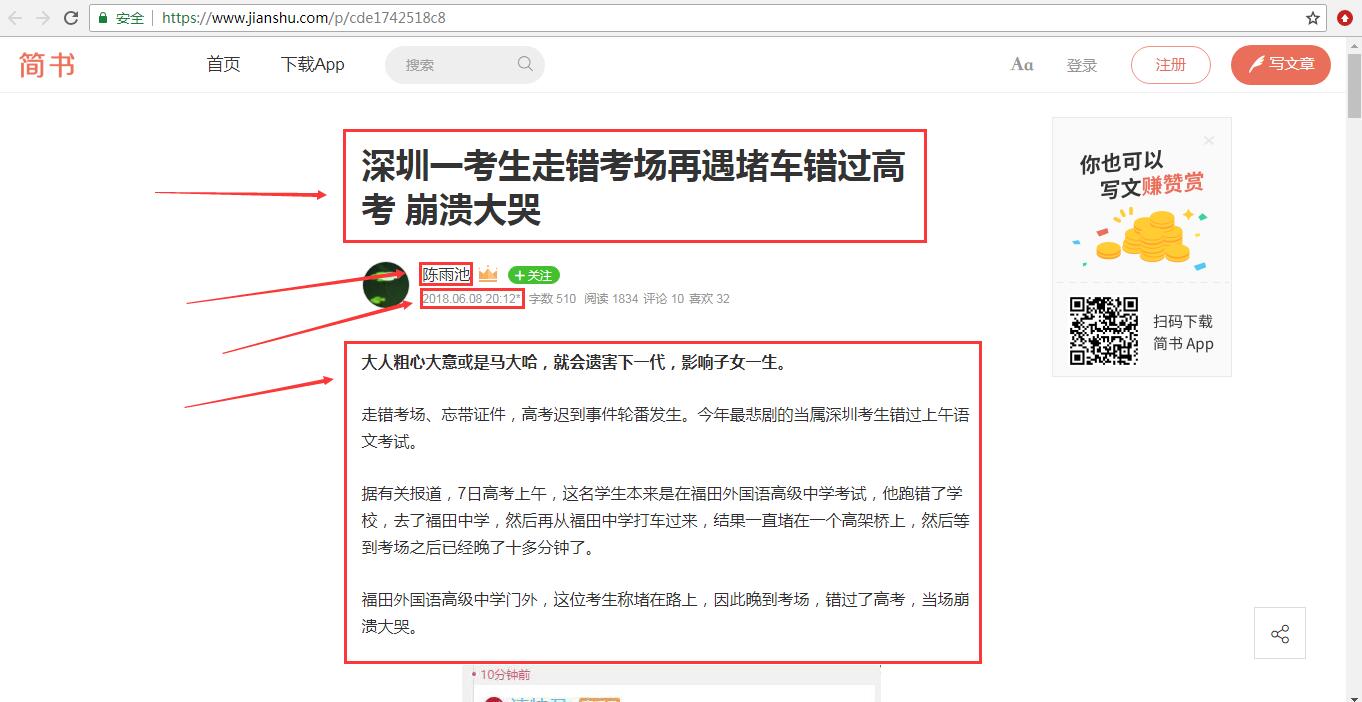
1 | def parse_detail(self, response): |
items.py 中设置存储模板
在上面已经决定了要采集者四个信息,那么在 item.py 中设置好这四项。1
2
3
4
5class JianshuItem(scrapy.Item):
title = scrapy.Field()
pub_name = scrapy.Field()
release_time = scrapy.Field()
content = scrapy.Field()
最后在 parse_detail 尾部加入以下代码,再将 item 返回去。1
2item = JianshuItem(title=title, pub_name=pub_name, release_time=release_time, content=content)
yield item
pipelines.py
到这里就可以运行一下程序了,看一下是否能正常输出我们采集的信息。

可以看到这里可以正常爬取数据,接下来需要将其存入数据库。存入数据库需要在 pipelines.py 中编写相应的代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class JianshuMongoDBPipeline(object):
def __init__(self):
self.DB_URI = 'localhost'
self.DB_PORT = 27017
self.client = pymongo.MongoClient(self.DB_URI, self.DB_PORT)
self.db = self.client['jianshu']
self.collection = self.db['jianshu_spider']
def process_item(self, item, spdier):
try:
if self.collection.insert(dict(item)):
print('保存至MongoDB成功')
else:
print('保存至MongoDB失败!')
except Exception as error:
print(error)
return item
在 pipelines.py 中写好 MongoDB 部分后,在 settings.py 中将对应的 pipelines 打开。
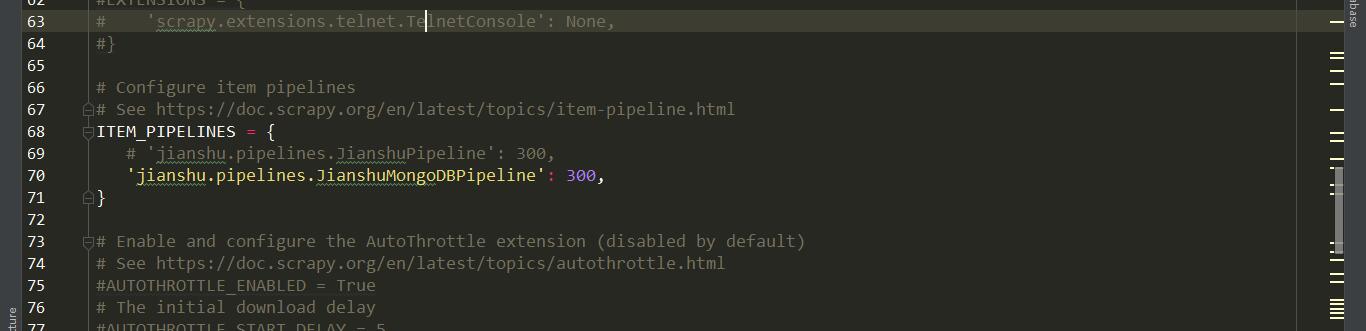
然后重新运行 start.py ,启动爬虫。
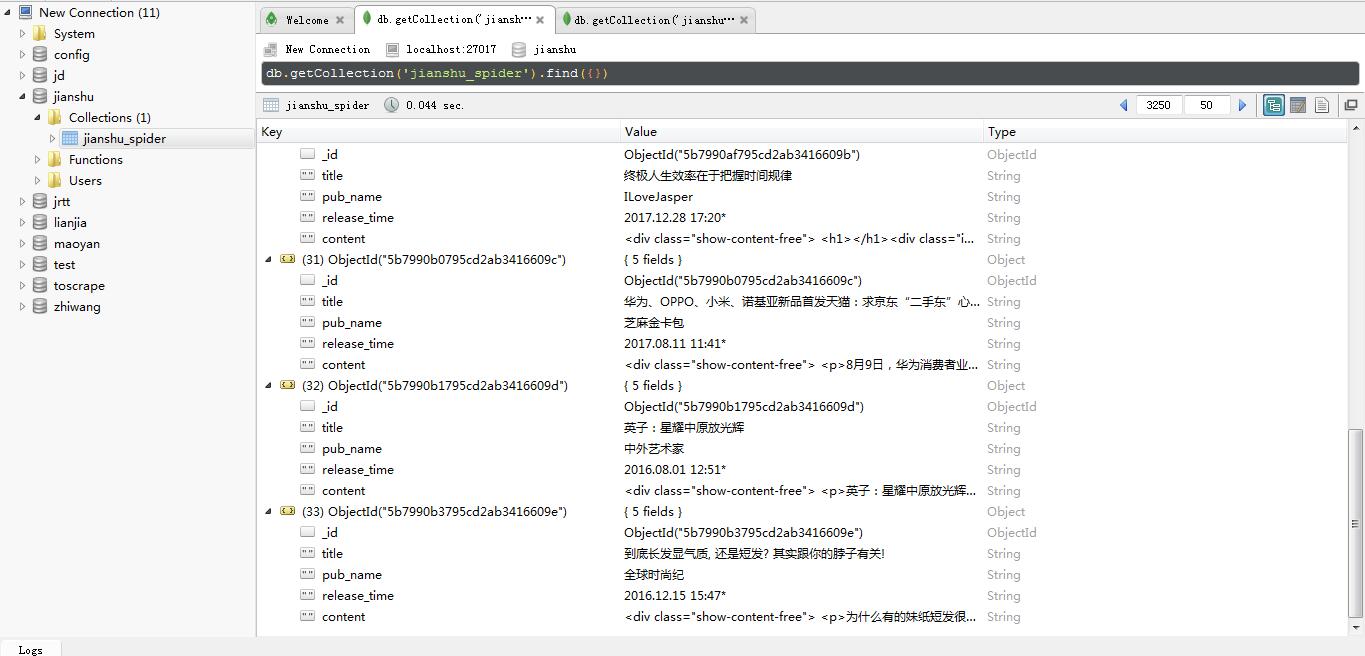
启动爬虫后,一直没有遇到反爬措施,运行了大概30分钟, ROBO 3T 管理工具得到的数据有3300条。感觉速度还是慢,有待优化(突然发现在 settings.py 中设置了1s延时….关掉之后快多了。。 )