![]()
前面的爬虫都是静态页面,遇到动态页面该如何爬取,当时困惑了好久,不知道如何下手,参考了几篇其他大佬的文章,才慢慢有一点懂。
这次的网页是动态加载的今日头条街拍图集网页。看了崔大大的教程,自己动手码一下代码,熟悉一下动态页面的爬虫步骤。
动态页面肯定不能像静态页面一样直接取数据,因为它的数据都是通过 js 渲染进来的,因此先找到对应的数据 js 文件。
首先,先来规划下步骤:
1.观察 js 请求,查看数据通过哪个文件传输。
2.对 js 文件进行请求,获得信息。
3.提取数据,对数据进行处理。
查看 js 请求
打开今日头条,搜索框内输入关键词“街拍”,跳转到街拍页面,往下拉,能看到图片一直在加载新的,而网址没有改变,动态的没错了,打开 F12 ,网页继续往下拉,Network 下出现了新的请求,并且这些请求构造都差不多,随便点击一个请求,打开 Preview ,里面是 json 格式的,其中有图片标题,也有图片的 url 信息,看到里面就是想要采集的数据,要找的就是它。
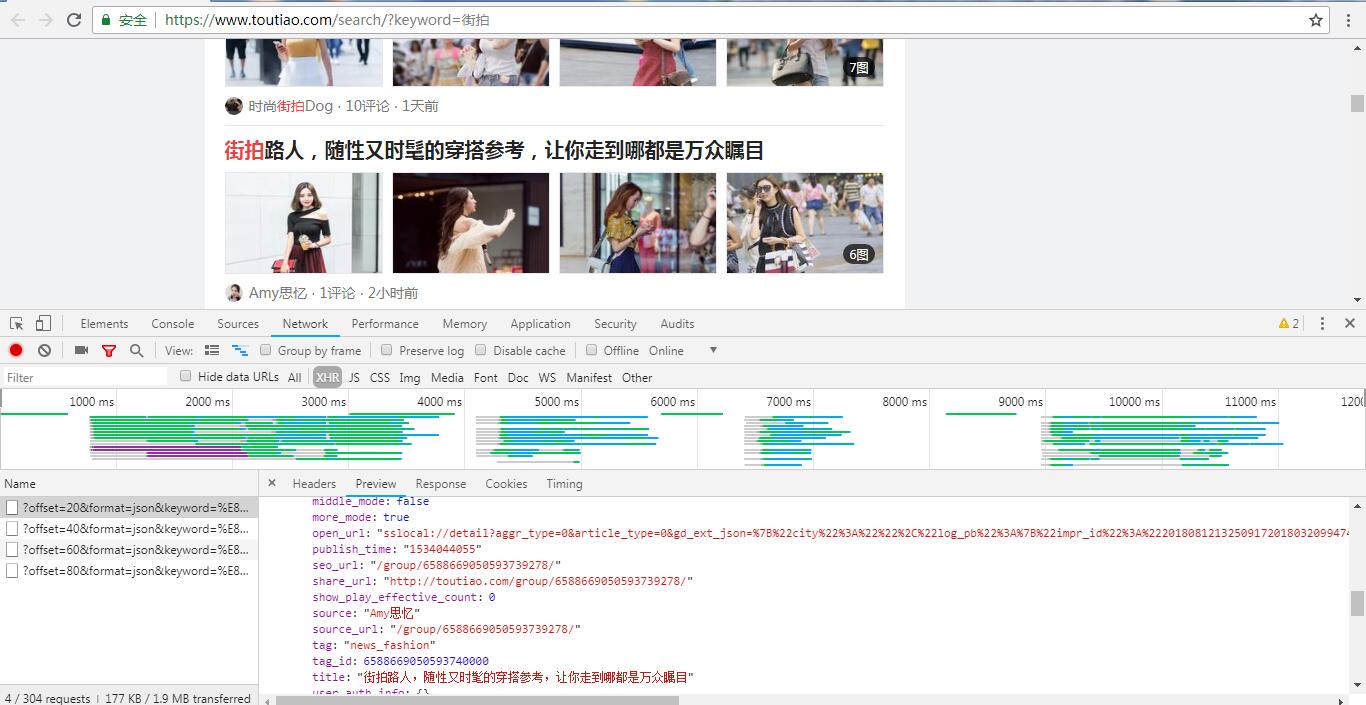
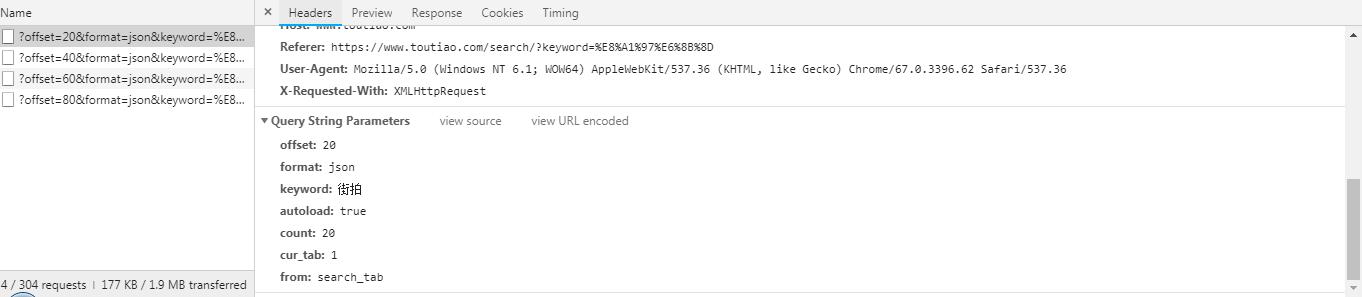
请求方式为 GET , 再来看下 Form Data ,有 offset , format , keyword , autoload , count , cur_tab , from 这几个参数,offset 是偏移量,也就是一共刷新出来的图片数量,keyword 是关键词, count 是每一页刷新出来的图片数量, 其它参数没什么重要意义,构造网址时直接加上去就行了。
对js进行请求
想要对 js 进行请求,需要先对网址进行构造。
1 | from urllib.parse import urlencode |
构造完毕,对网址进行请求。1
2
3
4# 对网址进行请求,获取到的json格式
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
提取信息
经过上一步对 js 进行请求后,得到和之前看到的 Preview 里面一样的信息,开始对数据进行提取处理。
1 | json = response.json() |
保存数据
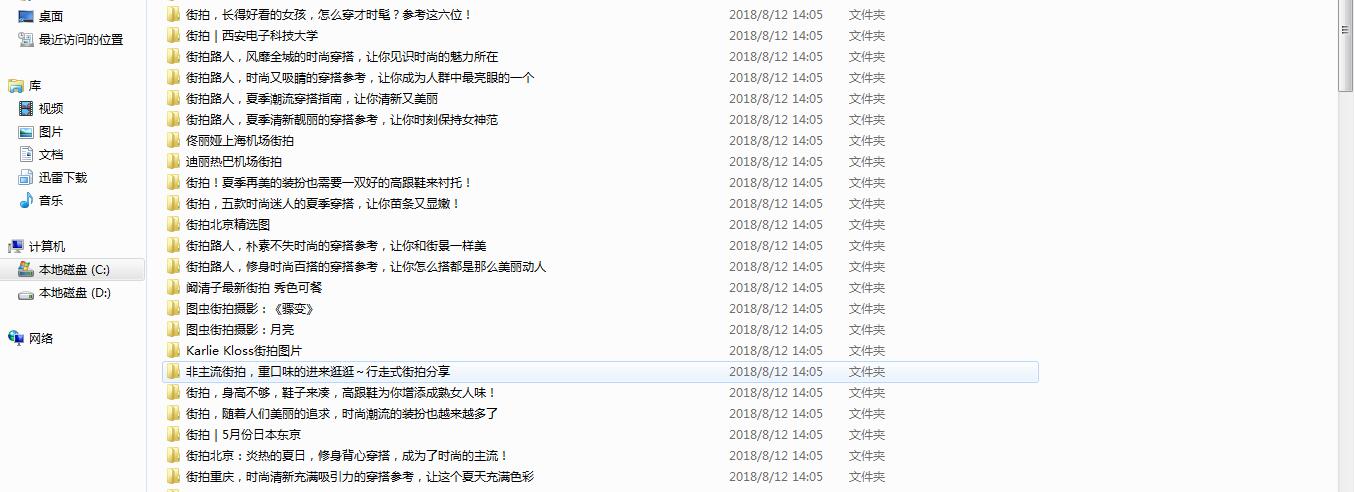
保存到本地文件夹
1 | import os |

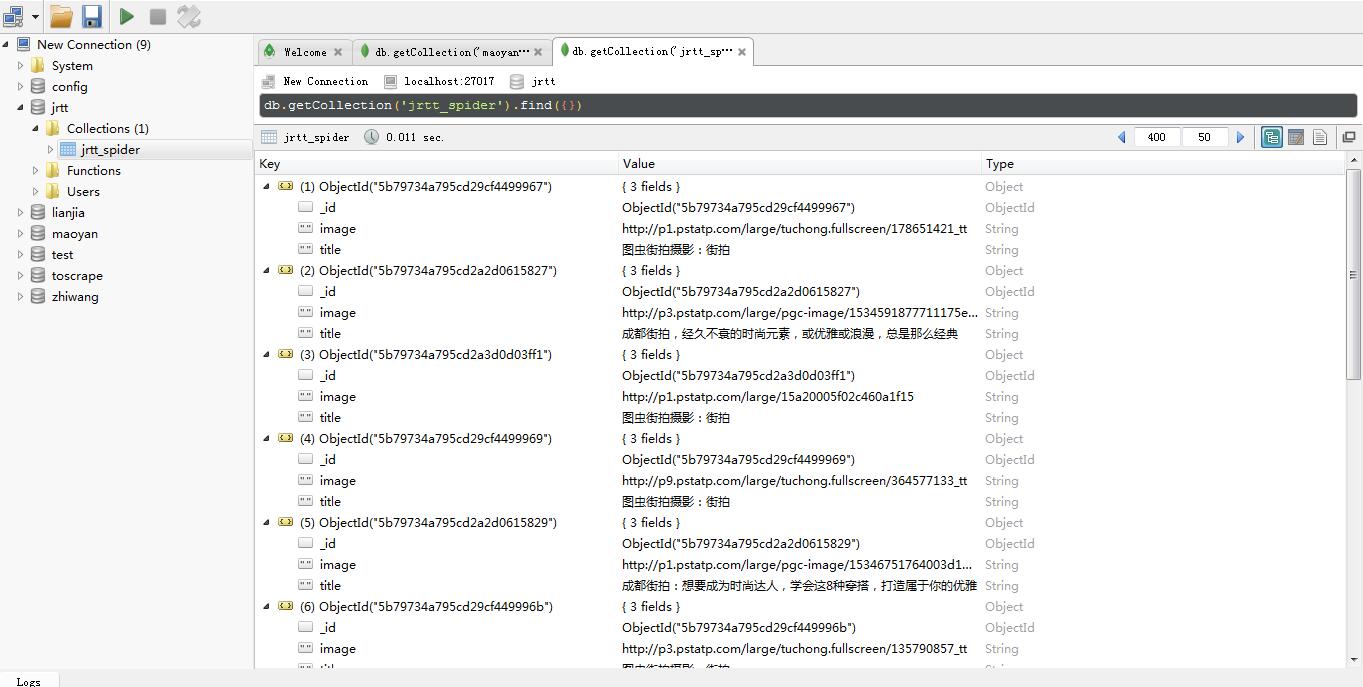
保存到 MongoDB 数据库
1 | def save_to_mongo(data): |
完整代码
1 | import os |