![]()
网页分成静态网页和动态网页:
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。静态网页相对更新起来比较麻烦,适用于一般更新较少的展示型网站。一般是网站呈现出来后网站的内容及结构就不会再发生改变了。
而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的能链接数据库,将数据库中的内容展现在页面中,同时允许用户与网站进行交互。我第一个接触的爬虫小项目就是猫眼爬虫。
因为猫眼网站是静态网站,因此我们只要先拿到原网址,获取内容后进行解析,再去分析多页信息等操作就可以了,作为入门项目非常简单。
写每个工程都要有明确思路,对于这个项目,步骤有:
1.获取到网页源代码。
2.使用 bs4 , xpath 等工具解析内容,提取想获取的内容。
3.分析网页如何进行翻页操作,构造翻页的网址,继续提取内容。
4.提取出的信息该如何处理(保存至文件或者数据库)
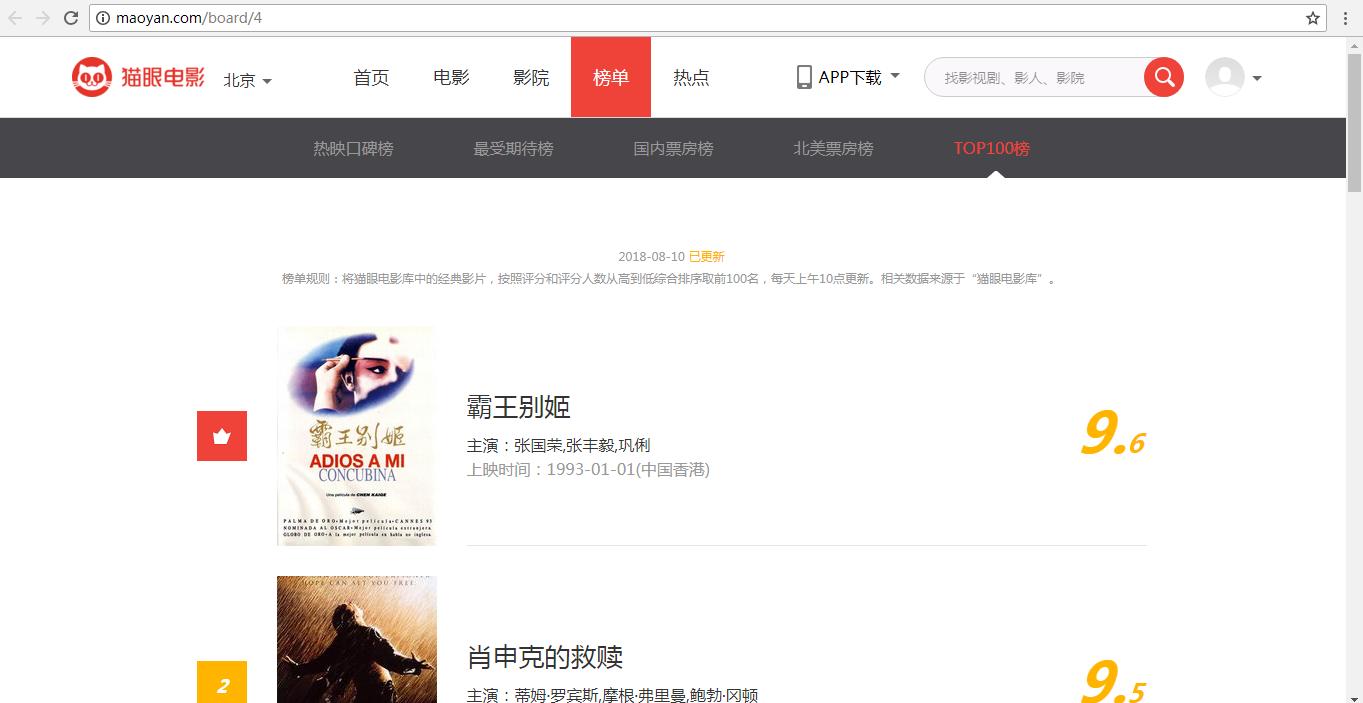
排行榜网址 http://maoyan.com/board/4
网站首页如下图所示:
获取网页源代码
1 | import requests |
提取信息
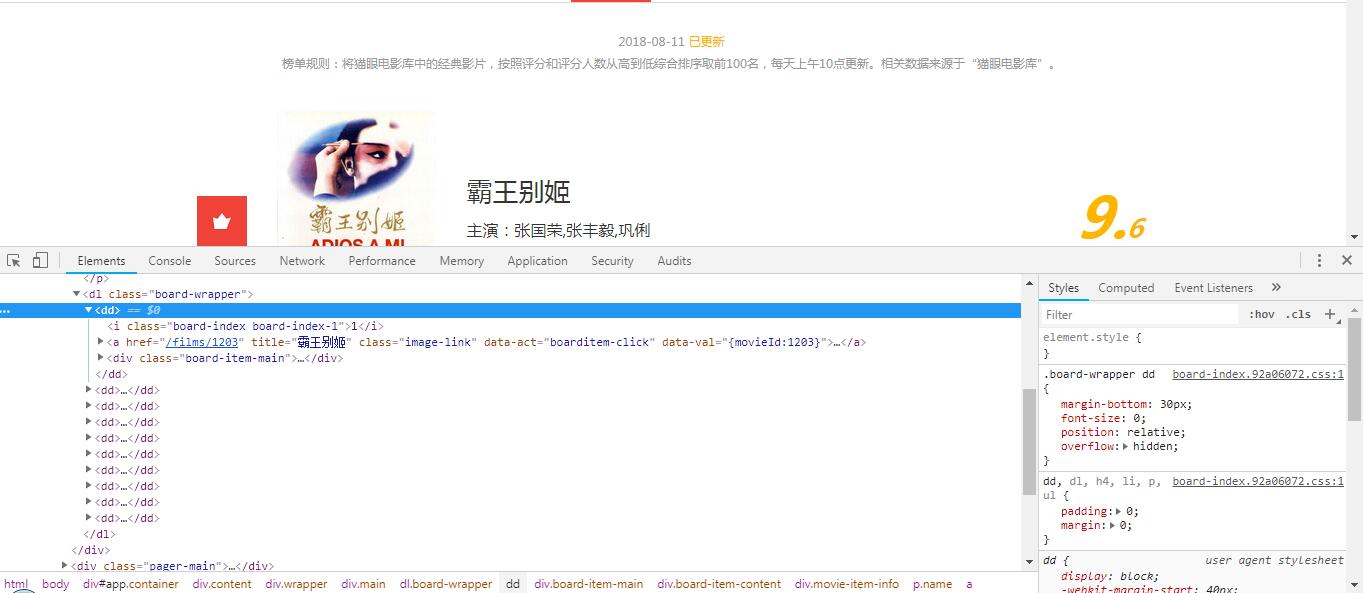
要提取各个电影的排名,影片名称,演员,上映时间,评分信息,打开 F12 开发工具,发现电影信息都被放在一个个 dd 标签内,因此使用 bs 的 select 方法,选中 dd 标签,select 输出是列表,可以迭代,所以继续用 for 循环遍历列表,再根据具体信息进行具体筛选,使用 .text 输出文本。
1 | soup = Beautifulsoup(response.text, 'lxml') |
分析网页的翻页操作
这里就直接点击下一页来查看网址的变化来找出页码规律,点击下一页发现网址后面出现了 offset 参数,每点击下一页,offset 后面的数值就+10,所以现在可以开始构造每一页的网址,来进行爬去整个 TOP100 排行榜,这里只爬取了前10页数据。1
2# 翻页网址的构造
final_url = 'http://maoyan.com/board/4?offset={}'.format(page)
上面是构造出的最终网址,通过传入 page 可以给网址赋予不同的操作,requests 再去请求就可以了。
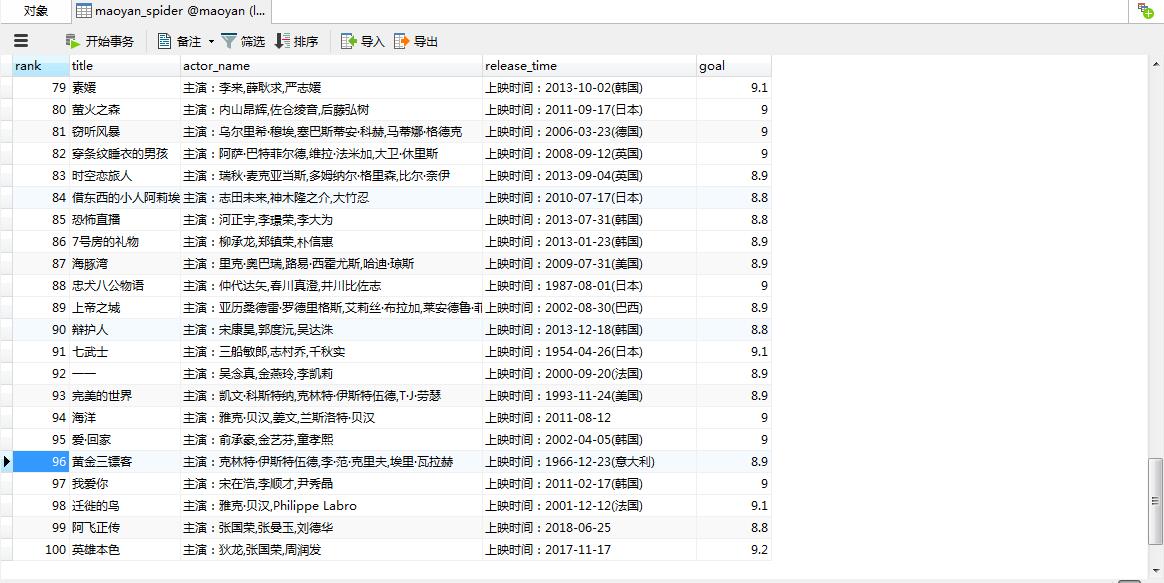
对提取数据的操作
提取数据后,可以存进文件里或者数据库中。
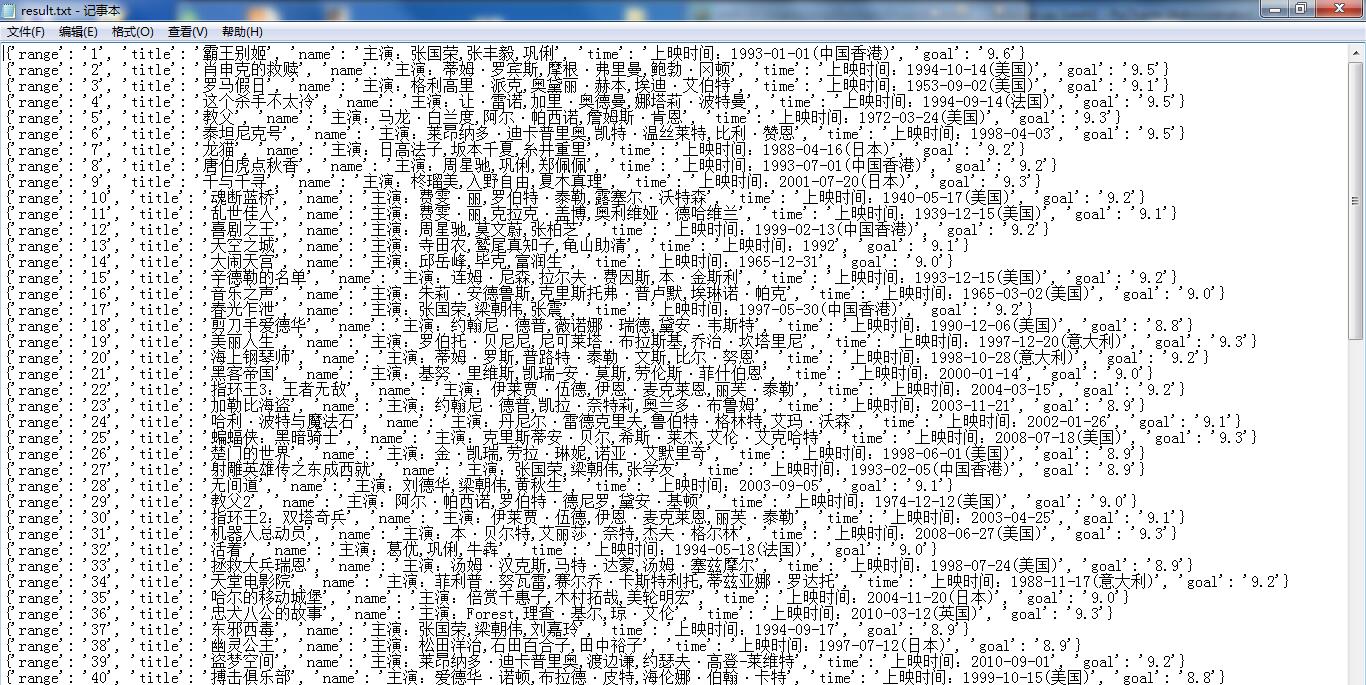
存进文件
1 | # 以追加方式,编码方式为utf-8 |
这样项目下就会生成一个 result.txt 文件,信息以字典方式存放入文件中。
将数据存入 mysql 数据库
1 | db = pymysql.connect('localhost', 'root', 'root', 'maoyan') |
将数据存入 mongoDB 数据库
1 | client = pymongo.MongoClient('localhost', 27017) |
完整代码
1 | import requests |