![]()
美团网也是动态加载的网页,但是我看了下,其美食信息也在源代码中有,因此可以按照Python爬虫–淘宝(2)其中的方式去爬美食信息。
步骤照搬:
1.获取网页源代码。
2.使用网页解析工具进行解析,构造翻页网址,提取所需信息。
3.整理并保存信息。
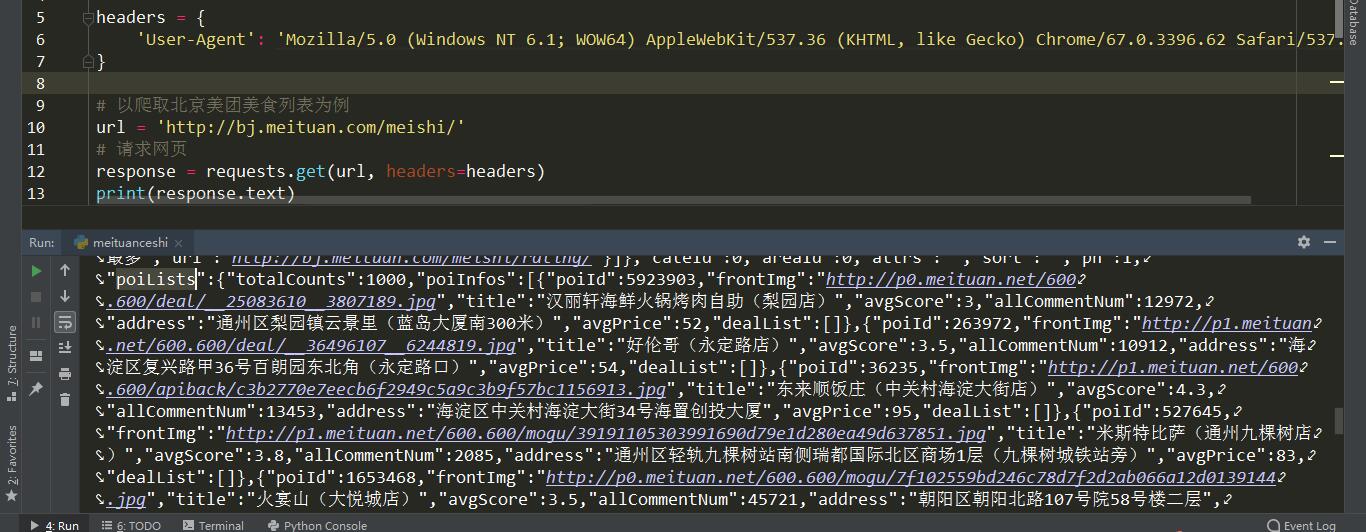
获取网页源代码
1 | import requests |
提取信息
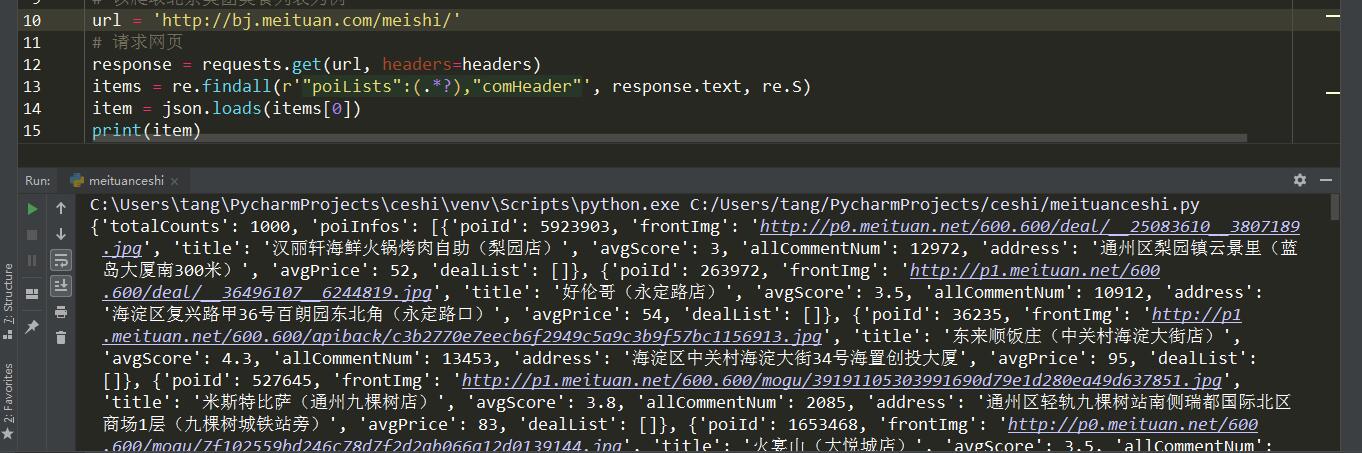
在上一步操作得到源代码之后,仔细观察,可以看到带有商家信息的部分为一段 json 数据,这里稍有不同的是,我们可以直接在源代码中使用正则表达式匹配出含有商家信息的 json 信息。
匹配 json 数据段
1 | import json |
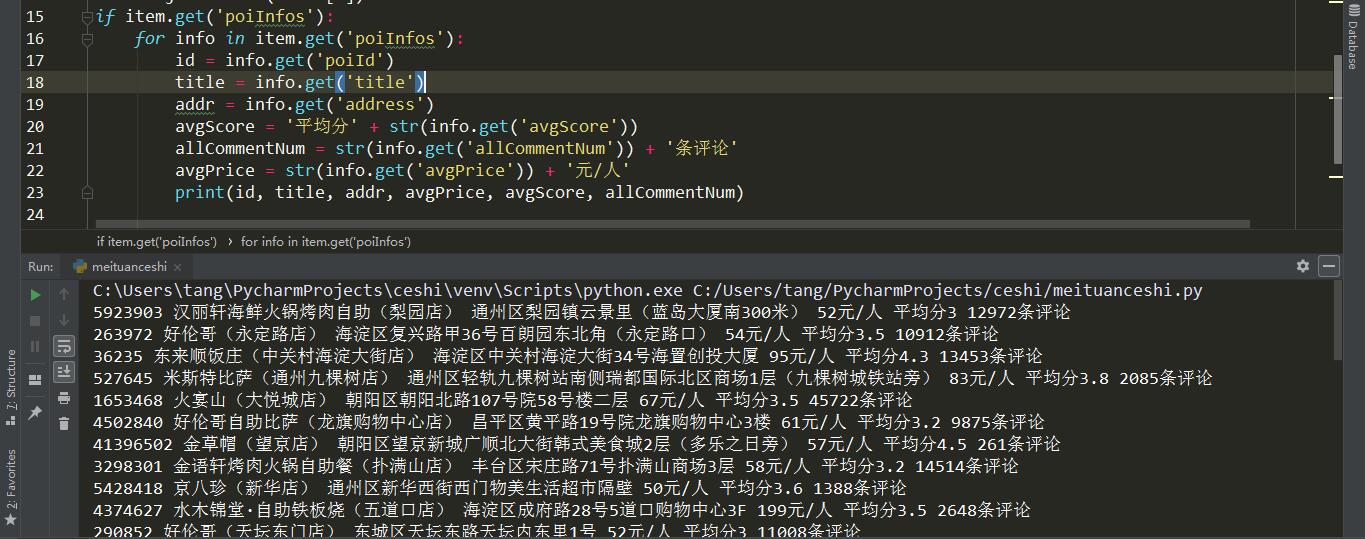
提取信息
1 | if item.get('poiInfos'): |
构造翻页网址
通过翻页找到页码规律,每个网页最后面 pn 后面的数字就是页码。1
2
3# 爬取 1-9 页美食信息
for page in range(1, 10):
url = 'http://bj.meituan.com/meishi/pn{}'.format(page)

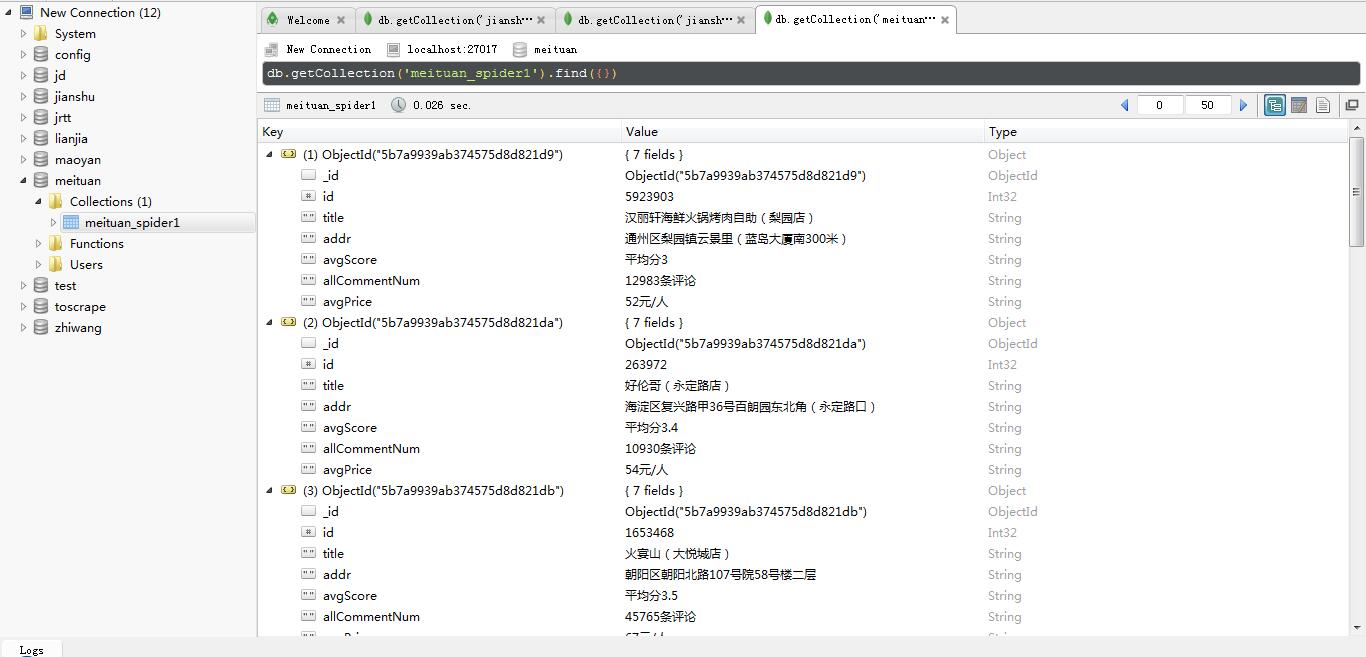
保存数据
保存到MongoDB数据库。
代码
1 | import requests |