![]()
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了网络抓取所设计的,也可以应用在获取 API 所返回的数据或者通用的网络爬虫。
Scrapy 是使用 Python 语言(基于 Twisted 框架)编写的开源网络爬虫框架。其简单易用、灵活易扩展、开发社区活跃,并且是跨平台的(支持Linux, MacOS, Windows)。
安装方式:pip 安装1
$ pip install scrapy
为了确认 Scrapy 被成功安装,可尝试在 python 命令行中将 scrapy 导入,如未报错,则安装成功。
1 | > import scrapy |
scrapy 框架结构
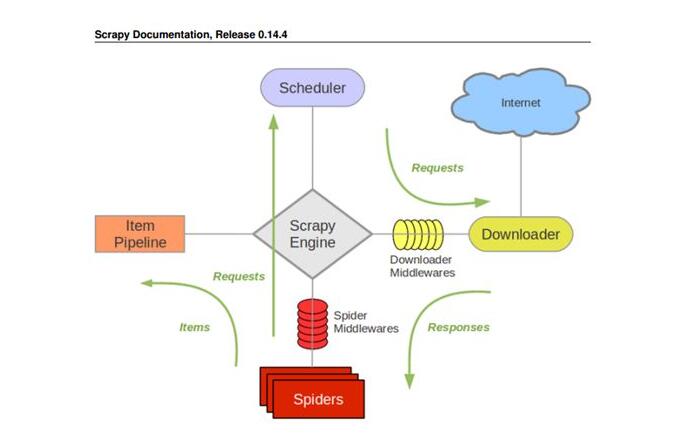
ENGINE 引擎,框架的核心,用于协调其它组件间工作
SCHEDULER 调度器,负责对 SPIDERS 提交的请求进行调度
DOWNLOADER 下载器,负责下载页面
SPIDERS 爬虫,负责提取页面中的数据,并产生对新页面的下载请求
MIDDLEWARES 中间件,负责对 Request 对象和 Response 对象进行处理
ITEM PIPELINE 数据管道,负责对爬取到的数据进行处理
scrapy 工作流程
1、引擎 ENGINE 从调度器中取出一个链接 URL 用于接下来的抓取
2、引擎 ENGINE 把 URL 封装成一个请求 Request 传给下载器 Downloader
3、下载器 Downloader 把资源下载下来,并封装成 Response
4、爬虫解析 Response
5、若解析出实体 Item,交给数据管道 Item Pipeline 做进一步处理
6、若解析出链接 URL,就把 URL 交给调度器等待抓取
scrapy 简单爬虫示例
专供爬虫初学者训练爬虫技术的网站 http://books.toscrape.com ,从这里开始。
创建项目
首先,来创建一个 scrapy 项目,在新建好的 scrapy_demo 文件夹下打开命令行工具,输入如下命令,在这里我创建好了名为 demo 的工程文件夹。1
$ scrapy startproject projectName
接下来再切换到项目文件夹根目录下,使用命令创建爬虫文件。可以看到提示已经使用 basic 模板创建了一个名为 books 的爬虫文件。
1 | cd projectName |

在此之后,使用 Pycharm 将整个 scrapy 项目导入。
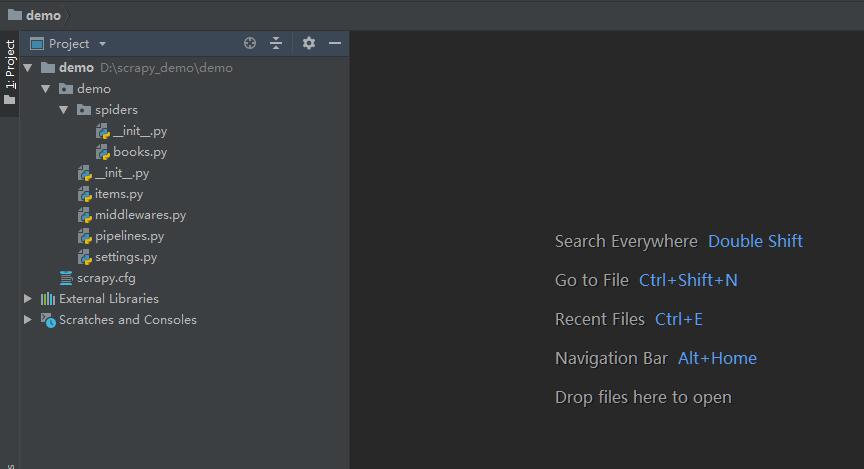
scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines.py 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
设置数据存储模板
要爬取的是各个图书的标题,价格信息。需要在 items.py 中设置数据存储模板。
1 | import scrapy |
编写爬虫
爬虫规则在 books.py 中编写。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import scrapy
from demo.items import DemoItem
class TestSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['toscrape.com']
# 爬虫起始页
start_urls = ['http://books.toscrape.com/catalogue/page-1.html']
def parse(self, response):
items = response.xpath("//article[@class='product_pod']")
for item in items:
title = item.xpath("./h3/a/text()").get()
price = item.xpath("./div[2]/p/text()").get()
item = DemoItem(title=title, price=price)
yield item
在运行爬虫之前,先在 settings.py 中设置好相关项,把 ROBOTSTXT_OBEY 置为 False ,并且打开浏览器模拟。
一切都设置好后,就可以运行爬虫了。为了方便运行,我习惯在项目根目录下新建一个 start.py 用来启动项目,其中代码如下。
1 | from scrapy import cmdline |
直接运行 start.py,得到如下结果。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
952018-08-20 17:30:36 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: demo)
2018-08-20 17:30:36 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.5.0, Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.0.2o 27 Mar 2018), cryptography 2.2.2, Platform Windows-7-6.1.7601-SP1
2018-08-20 17:30:36 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'demo', 'NEWSPIDER_MODULE': 'demo.spiders', 'SPIDER_MODULES': ['demo.spiders']}
2018-08-20 17:30:36 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-08-20 17:30:37 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-08-20 17:30:37 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-08-20 17:30:37 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-08-20 17:30:37 [scrapy.core.engine] INFO: Spider opened
2018-08-20 17:30:37 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-08-20 17:30:37 [py.warnings] WARNING: C:\ProgramData\Anaconda3\lib\site-packages\scrapy\spidermiddlewares\offsite.py:59: URLWarning: allowed_domains accepts only domains, not URLs. Ignoring URL entry http://toscrape.com/ in allowed_domains.
warnings.warn("allowed_domains accepts only domains, not URLs. Ignoring URL entry %s in allowed_domains." % domain, URLWarning)
2018-08-20 17:30:37 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-08-20 17:30:37 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://books.toscrape.com/catalogue/page-1.html> (referer: None)
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£51.77', 'title': 'A Light in the ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£53.74', 'title': 'Tipping the Velvet'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£50.10', 'title': 'Soumission'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£47.82', 'title': 'Sharp Objects'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£54.23', 'title': 'Sapiens: A Brief History ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£22.65', 'title': 'The Requiem Red'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£33.34', 'title': 'The Dirty Little Secrets ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£17.93', 'title': 'The Coming Woman: A ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£22.60', 'title': 'The Boys in the ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£52.15', 'title': 'The Black Maria'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£13.99', 'title': 'Starving Hearts (Triangular Trade ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£20.66', 'title': "Shakespeare's Sonnets"}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£17.46', 'title': 'Set Me Free'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£52.29', 'title': "Scott Pilgrim's Precious Little ..."}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£35.02', 'title': 'Rip it Up and ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£57.25', 'title': 'Our Band Could Be ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£23.88', 'title': 'Olio'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£37.59', 'title': 'Mesaerion: The Best Science ...'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£51.33', 'title': 'Libertarianism for Beginners'}
2018-08-20 17:30:37 [scrapy.core.scraper] DEBUG: Scraped from <200 http://books.toscrape.com/catalogue/page-1.html>
{'price': '£45.17', 'title': "It's Only the Himalayas"}
2018-08-20 17:30:37 [scrapy.core.engine] INFO: Closing spider (finished)
2018-08-20 17:30:37 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 315,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 5889,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 8, 20, 9, 30, 37, 857663),
'item_scraped_count': 20,
'log_count/DEBUG': 22,
'log_count/INFO': 7,
'log_count/WARNING': 1,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 8, 20, 9, 30, 37, 96620)}
2018-08-20 17:30:37 [scrapy.core.engine] INFO: Spider closed (finished)
可以看到,scrapy 在经过初始化之后开始爬虫,并且输出了所需的价格和标题信息。
保存数据
暂不做介绍。