准备工作
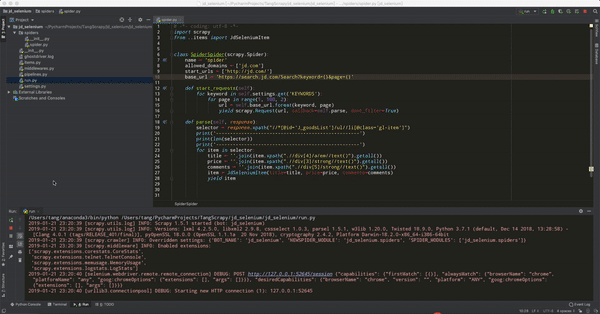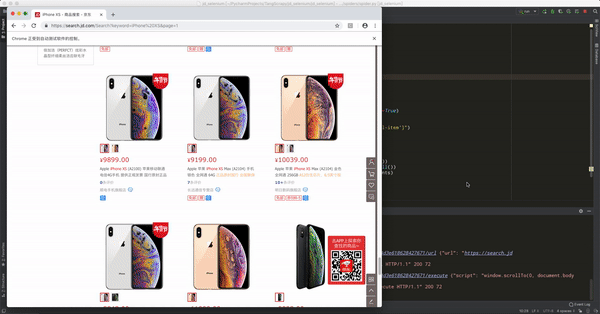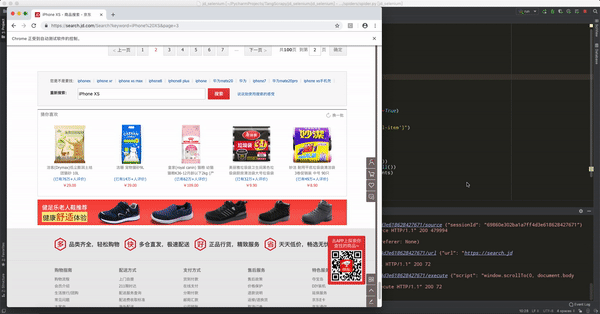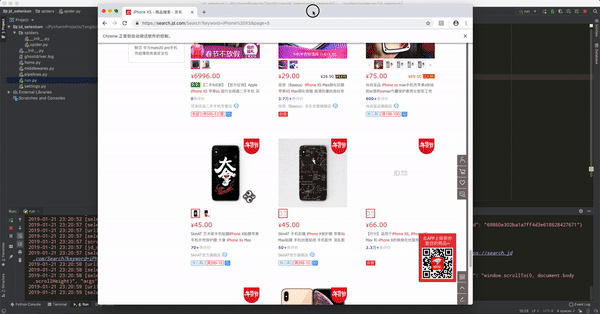
闲话不多说,准备工作都已经做好了。确保电脑上 chromedriver 和 selenium 框架都已安装好。新建一个名为 jd_selenium 的项目,然后新建一个爬虫,修改 settings.py 中的 ROBOTSTXT_OBEY = False,最后在项目根目录下新建启动文件 run.py。
定义 Item
1 | import scrapy |
初步实现 Spider 的 start_requests() 方法,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14import scrapy
from urllib.parse import quote
class SpiderSpider(scrapy.Spider):
name = 'spider'
allowed_domains = ['jd.com']
base_url = 'https://search.jd.com/Search?keyword='
def start_requests(self):
for keyword in self.settings.get('KEYWORDS'):
for page in range(1, 100, 2):
url = self.base_url.format(keyword, page)
yield scrapy.Request(url, callback=self.parse, dont_filter=True)
首先定义了一个 base_url,即商品列表的 URL,其后拼接一个搜索的关键词就是该关键词在京东的搜索结果商品列表页面。
关键词用 KEYWORDS 标识,定义为一个列表。定义在 settings.py 里面,如下所示:1
KEYWORDS = ['iPhone XS']
在 start_requests() 方法里,首先遍历了关键词,再遍历了页码,构造并生成了 Request。
对接 Selenium
接下来需要成功处理这些请求的抓取。这里选择对接 Selenium 进行抓取,采用 Downloader Middleware 来实现。这里浏览器使用的是 Chrome 的 headless 模式。在 Middleware 里面的 process_request() 方法里对每个抓取请求进行处理,启动浏览器并进行页面渲染,再将渲染后的结果构造一个 HtmlResponse 对象返回。代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43import time
from scrapy import signals
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from logging import getLogger
from scrapy.http import HtmlResponse
class SeleniumMiddleware():
# 加入了 chrome headless 模式
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
def __init__(self):
self.logger = getLogger(__name__)
self.timeout = 10
self.browser = webdriver.Chrome(chrome_options=self.chrome_options)
self.browser.set_page_load_timeout(self.timeout)
self.wait = WebDriverWait(self.browser, self.timeout)
def __del__(self):
self.browser.close()
def process_request(self, request, spider):
"""
用 Chrome 抓取页面
:param request: Request 对象
:param spider: Spider 对象
:return: HtmlResponse
"""
self.logger.debug('Chrome is Starting')
page = request.meta.get('page', 1)
try:
self.browser.get(request.url)
except TimeoutException as e:
print('请求超时')
time.sleep(2)
return HtmlResponse(url=request.url, body=self.browser.page_source, encoding='utf-8', request=request)
这样就定义好了一个 Selenium 中间件,然后在 settings.py 中设置调用 SeleniumMiddleware,如下所示:1
2
3DOWNLOADER_MIDDLEWARES = {
'jd_selenium.middlewares.SeleniumMiddleware': 543,
}
解析页面
Response 对象回传给 Spider 中的回调函数进行解析。因此这步来实现其回调函数,对网页来进行解析,代码如下所示。1
2
3
4
5
6
7
8
9
10
11def parse(self, response):
selector = response.xpath("//*[@id='J_goodsList']/ul//li[@class='gl-item']")
print('---------------------------------------------------')
print(len(selector))
print('---------------------------------------------------')
for item in selector:
title = ''.join(item.xpath(".//div[4]/a/em//text()").getall())
price = ''.join(item.xpath(".//div[3]/strong//text()").getall())
comments = ''.join(item.xpath(".//div[5]/strong//text()").getall())
item = JdSeleniumItem(title=title, price=price, comments=comments)
yield item

在上面代码中,对 selector 的长度进行了输出,因为看到的商品数量明显少于直接打开浏览器的商品结果,后来发现在京东输入关键词点击搜索之后,页面的返回是分成两个步骤,它首先会直接返回一个静态的页面,页面的商品信息是30个,之后,当我们鼠标向下滑动时,后台会通过 ajax 技术加载另外的30个商品,因此直接打开浏览器看到的商品列表其实是分两次加载出来的,而且只是在鼠标下滑到一定位置的时候才会加载那另外的30个商品。
执行 js 脚本
因此,为了实现鼠标下滑的现象,需要 Selenium 执行一段 js 代码,将网页下拉到一定位置。
修改后的 SeleniumMiddleware 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def process_request(self, request, spider):
"""
用 Chrome headless 抓取页面
:param request: Request 对象
:param spider: Spider 对象
:return: HtmlResponse
"""
self.logger.debug('Chrome is Starting')
page = request.meta.get('page', 1)
try:
self.browser.get(request.url)
self.browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
except TimeoutException as e:
print('请求超时')
self.browser.execute_script('window.stop()')
time.sleep(2)
return HtmlResponse(url=request.url, body=self.browser.page_source, encoding='utf-8', request=request)
代码修改后运行程序,这次选择器的长度变成了59,正常应该是60,可能是哪里出问题了。-.-

存入数据库
实现一个 Item Pipeline,将结果保存到 MongoDB,如下所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import pymongo
from .settings import mongo_uri, mongo_db
class JdSeleniumPipeline(object):
def __init__(self):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
self.collection = self.db['collection']
def process_item(self, item, spider):
self.collection.insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
编写完成需要在 settings.py 中开启调用。如下所示:1
2
3ITEM_PIPELINES = {
'jd_selenium.pipelines.JdSeleniumPipeline': 300,
}
其中 mongo_uri 和 mongo_db 分别定义:1
2mongo_uri = 'localhost'
mongi_db = 'jd_scrapy'
如图所示,已经将数据存入了数据库。

运行效果