![]()
在进行模拟登录之前,应该先对网站登录的原理有所了解,首先在 Chrome 浏览器中进行一次实际的登录操作,再来观察浏览器和网站服务器是如何交互的。
在这里我使用 豆瓣网 作为此次模拟登录的示例。
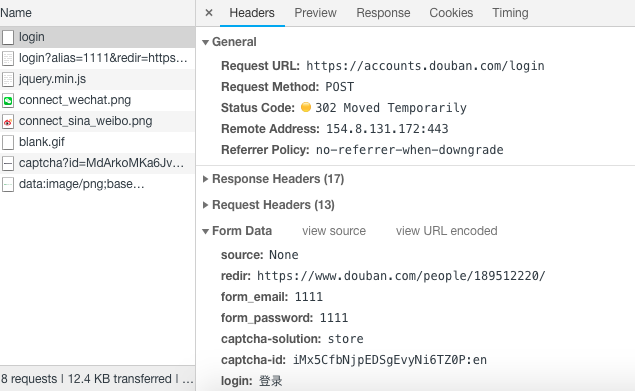
首先打开 F12 开发者模式,在登录表单中输入用户名和密码(这里我的验证码是因为我尝试次数过多出现),点击登录按钮,观察控制台中 Network 下第一条请求,其为一条 post 请求,且参数在图中有所展示,那么如果需要模拟登录,就需要对这些参数进行构造。
登录的核心其实就是向服务器发送含有登录表单数据的 HTTP 请求(通常是 POST),在 Scrapy 中提供了一个 FormRequest 类(Request的子类),专门用于构造含有登录表单的请求,FormRequest 的构造器方法有一个 formdata 参数,接收字典形式的表单数据。
在本篇文章中,我先模拟登录到网站后,跳转至个人中心,然后修改我的个人签名。
模拟登录
要构造 post 请求的参数,来看上图参数中 source, redir 和 login 都是固定值,form_email, form_password 分别为用户名和密码,captcha-solution 是图片验证码的字符,captcha-id 就先去网页源代码中寻找,如下图。

在这里我将 start_urls 设置为我的个人详情页,模拟登录这里需要重写 start_requests 方法,因为如果不去重写这个方法,那么 scrapy 就会对我的个人详情页直接进行请求。
FormRequest 的 from_response 方法需传入一个 Response 对象作为第一个参数,该方法会解析 Response 对象所包含的 form 元素,帮助用户创建 FormRequest 对象,并将隐藏 input 中的信息自动填入表单数据。使用这种方法,只需通过 formdata 参数填写账号和密码即可。这里使用 PIL 的 Image 方法将图片展示出来,人工识别并输入到程序中,程序继续进行登录。
1 | # 模拟登录 |
在 login 函数中,最后的 FormRequest 的回调函数是 parse_after_login 函数,代码如下。
1 | def parse_after_login(self, response): |
修改签名
在登录成功之后,需要先跳转到我的个人详情页面,再进行修改签名操作。
先手动修改签名一次,观察浏览器的请求过程,如图所示。点击修改后,浏览器中这条 POST 请求的 formdata 只有两个参数,一个 signature 就是我们正在修改的签名。
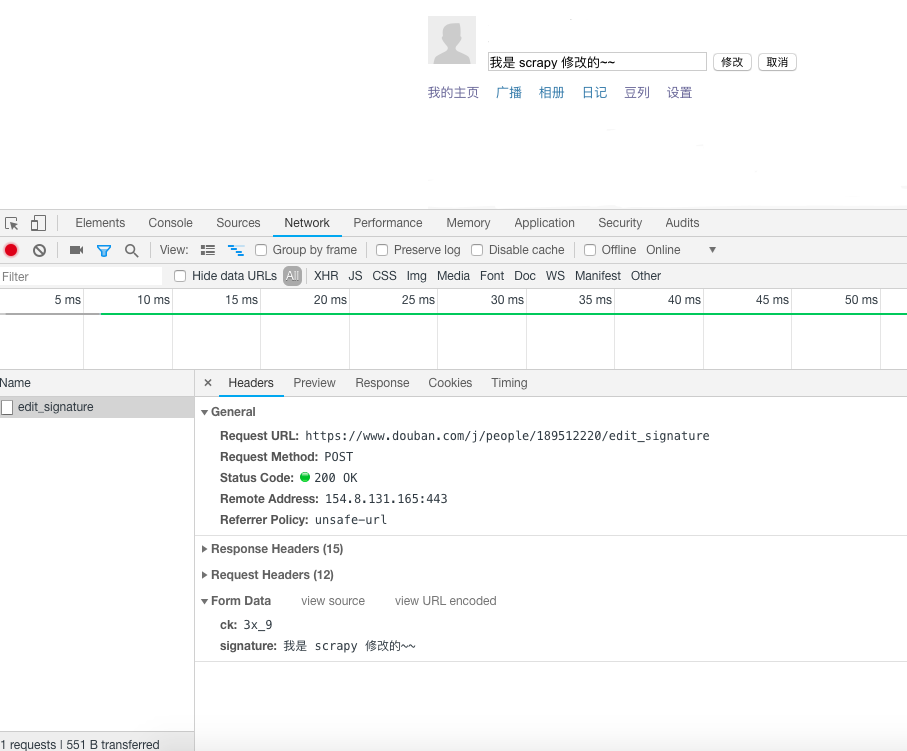
另一个是 ck 参数,ck 参数在网页源代码中同样可以找到,如下图。

有了修改签名的两个参数,我们就可以构造修改签名的 FormRequest 了。
1 | def parse_after_login(self, response): |
完整代码
1 | # -*- coding: utf-8 -*- |