![]()
淘宝网也是动态加载的网页,虽然其页面数据也是通过 Ajax 获取的,但是若想像前面一样去分析 Ajax ,在淘宝这里是很复杂的,因为其参数会包含加密密钥,自己构造 Ajax 参数过于复杂。所以并不建议使用和爬取今日头条一样的方法来爬取淘宝。
先来分析下淘宝的接口,来观察 Ajax 复杂程度。
打开淘宝,再打开开发者工具,搜索关键词 python ,截获 Ajax 请求,这里看到只有一条请求,并且其内容为 json 形式的商品信息。
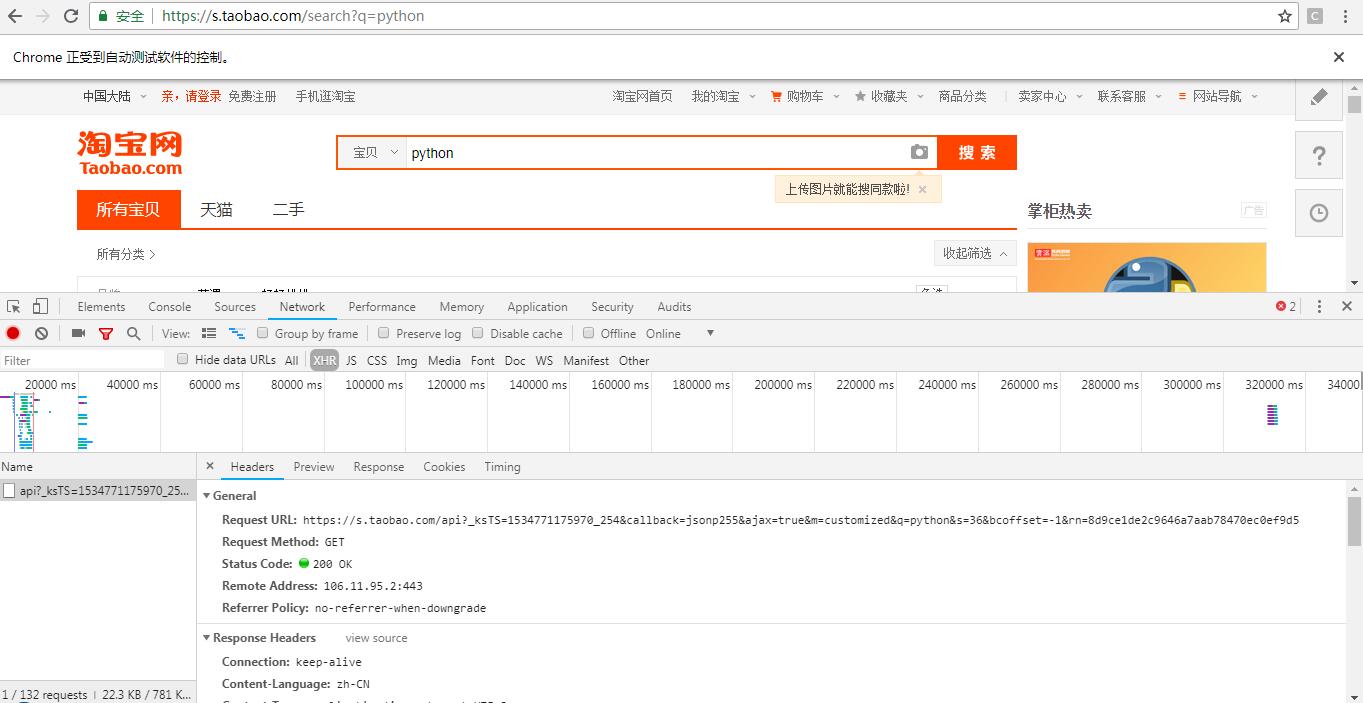
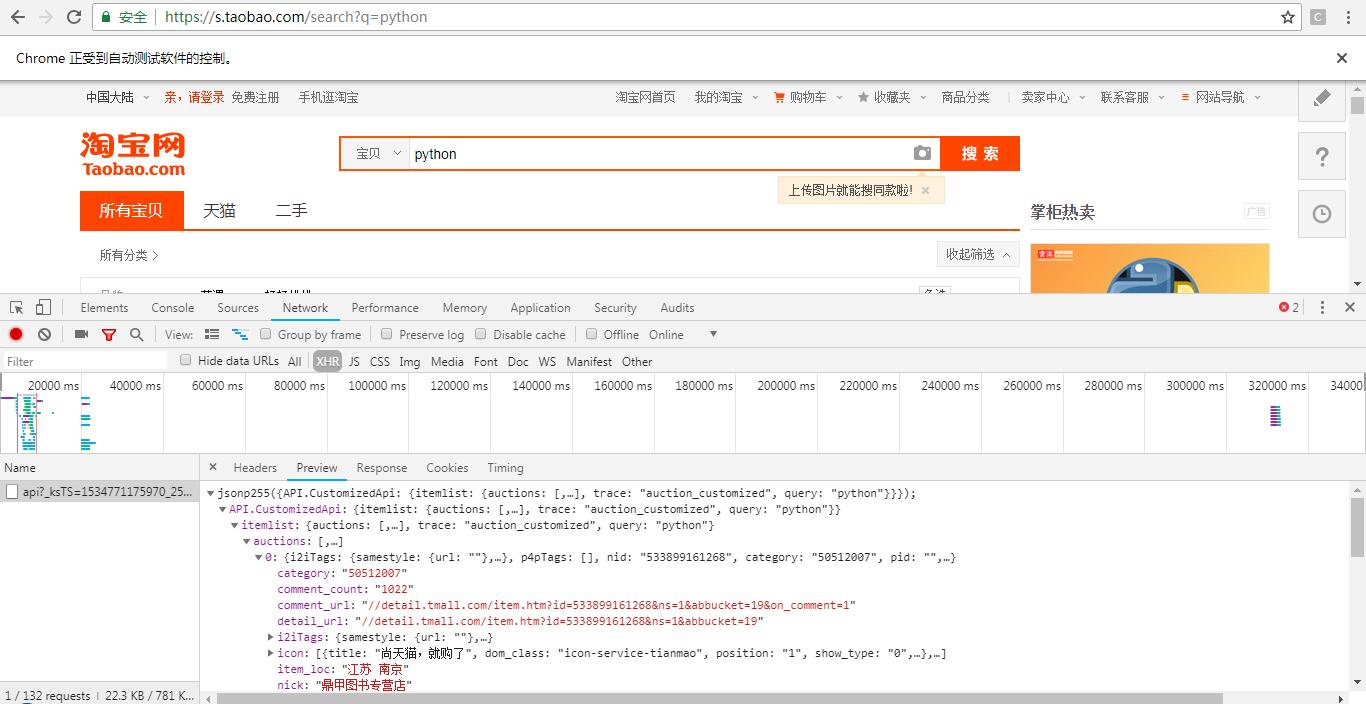
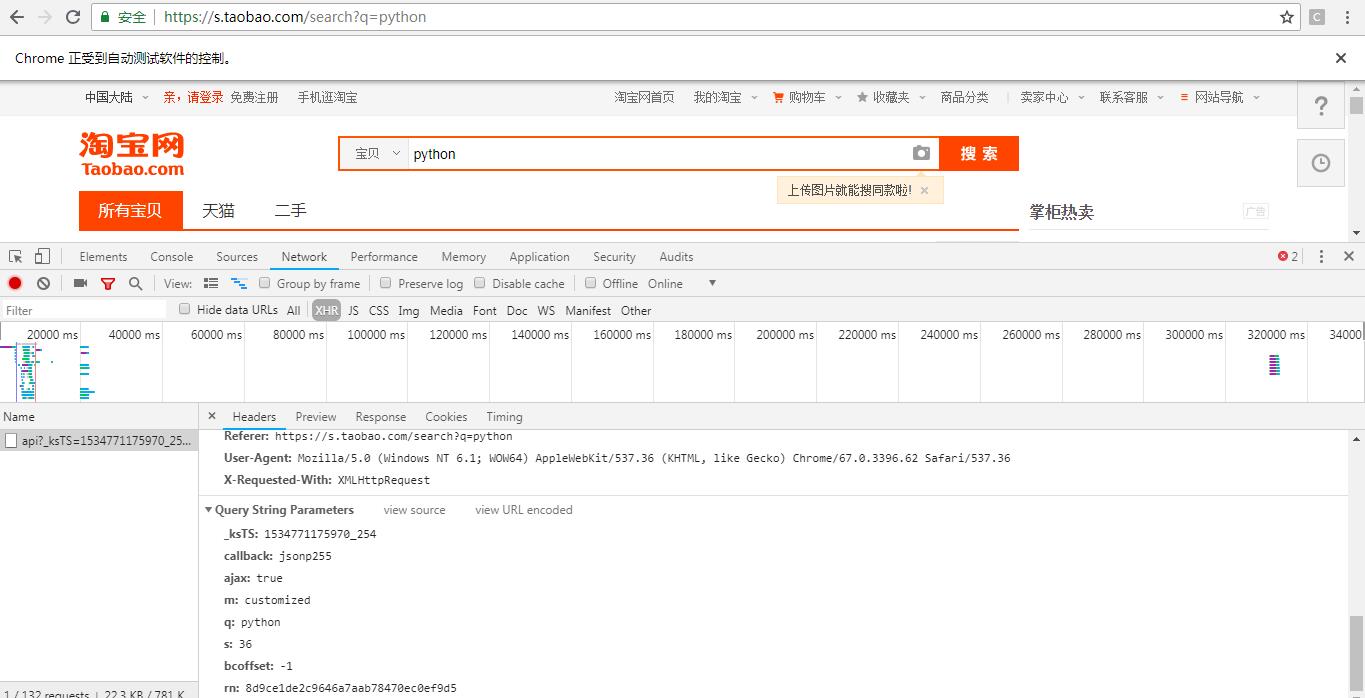
再来查看其构造参数。可以看到其中的 ksTS 和 rn 参数不能直接找到其规律,如果想找,只会消耗大量时间。但是如果使用 selenium 来模拟浏览器操作的话,那就不需要再关注这些参数了。因此接下来的部分使用 selenium 来爬取淘宝宝贝信息。
selenium 是一个用于 Web 应用程序测试的工具。Selenium 直接运行在浏览器中,就好像真实用户在操作一样,因此在爬虫中主要用来解决 js 渲染问题。其支持很多浏览器,常见的 Chrome, Firefox, ie,safari 和无头浏览器 phantomjs 。
这次就使用 selenium 这个工具来操作对淘宝商品的爬虫。
selenium 的使用方法步骤:首先导入所需要的包,然后声明浏览器对象,再去请求网页,最后进行查找节点等等操作。
导入所需要的包:1
from selenium import webdriver
声明浏览器对象(使用 Chrome 浏览器):1
browser = webdriver.Chrome()
访问网页1
2url = 'https://www.taobao.com'
browser.get(url)
下面来写整个项目,按照惯例,先列出步骤。
1.使用 selenium 访问淘宝商品列表网页,获取网页源代码。
2.使用网页解析工具采集所需数据。
3.导出并整理数据。
使用 selenium 获取网页源代码
1 | from selenium import webdriver |
获取所需数据
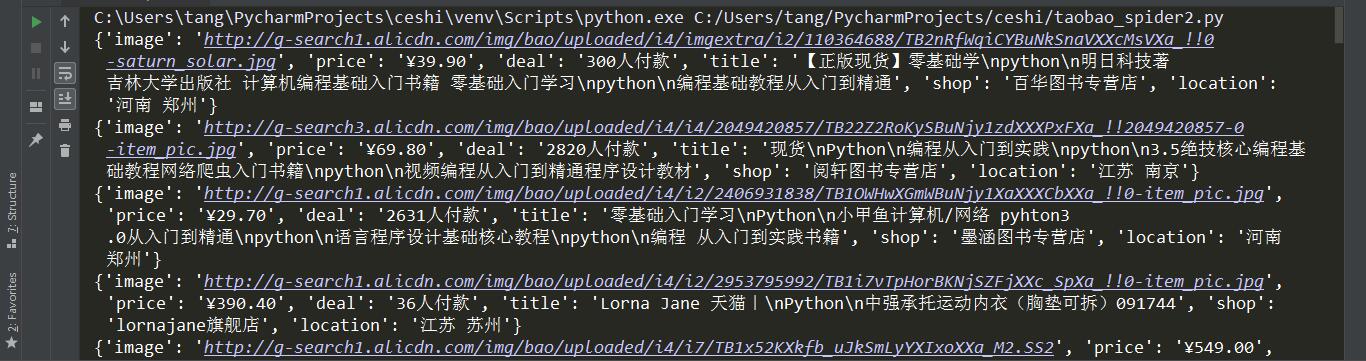
在商品列表页中,要爬取的信息有商品图片、商品价格、商品成交量、商品名称、店铺名称和位置这六项信息。
1 | from pyquery import PyQuery as pq |
获取到以下数据。
翻页
在 index_page 中首先访问了 url ,然后判断当前页码,如果大于1,就进行跳页操作,否则等待页面加载完成。
等待加载时,使用了 WebDriverWait 对象,它可以指定等待条件,这里指定为10s,如果在这个时间内成功匹配了等待条件,就立即返回结果并向下执行,否则就抛出超时异常。
比如在这里要等待商品信息加载出来,就制定了 presence_of_element_located 这个条件,然后传入 .m-itemlist .items .item 选择器,而这个选择器对应的页面内容就是每个商品的新消息块,如果加载成功了,就会执行后续的 get_products() 方法。
关于翻页操作,这里先获取了页码的输入框,赋值为 input ,然后再获取确定按钮,赋值为 submit 。获取到两个元素后,先调用 clear() 方法将页码输入框进行清空,再调用 send_keys() 方法将页码填充进去。
那么如何确定浏览器有没有跳转到对应的页码呢,可以看到,成功跳转到某一页时,当前页码会在网页底部高亮显示,因此可以拿到高亮显示的 css 选择器与当前传入的页码做对比,如果一致,则跳转成功。继续等待商品加载完成…1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34from urllib.parse import quote
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
wait = WebDriverWait(browser, 10)
KEYWORD = 'python'
def index_page(page):
try:
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
if page > 1:
# 页码输入框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input'))
)
# 页码确定按钮
submit = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit'))
)
input.clear()
input.send_keys(page)
submit.click()
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page))
)
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.m-itemlist .items .item'))
)
get_products()
except TimeoutException:
index_page(page)
保存数据到 MongoDB
1 | client = pymongo.MongoClient('localhost', 27017) |
采集到的数据如下。

完整代码
1 | from selenium import webdriver |