![]()
上一篇介绍了如何用 selenium 自动化工具去帮助爬取淘宝商品的各项数据,但是,我发现,淘宝的网页源代码中就包含有宝贝信息,信息被放在了 script 标签中,既然信息被包含在源代码中,那就证明可以通过正则或者其它的网页解析方式可以获取到需要的信息,因此这篇就来写一写对于淘宝商品来说更为简单的小爬虫。
这次的流程就比较简单了,先做好准备工作:
1.获取网页源代码。
2.使用网页解析工具进行解析,构造翻页网址,提取所需信息。
3.整理并保存信息。
获取网页源代码
1 | import requests |
通过 requests 的 get 方法请求网页之后,得到网页源代码。
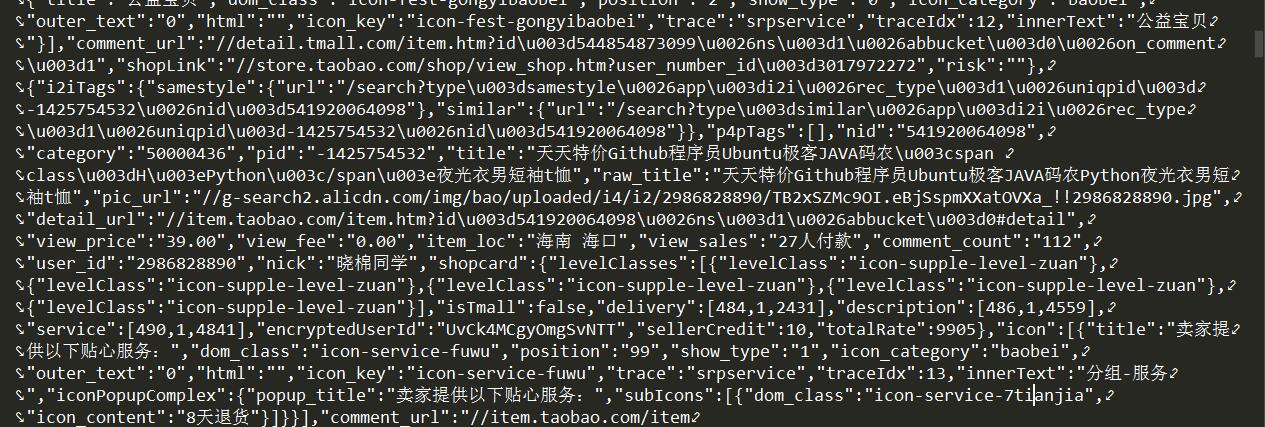
提取信息
1 | title = re.findall(r'"raw_title":"(.`?)"', response.text, re.I) |
在这里只对商品的标题,价格和发货地进行了正则匹配,因为它们都是列表,要想让宝贝信息都一一对应的显示出来,就要进行遍历,最后把宝贝信息都进行输出。
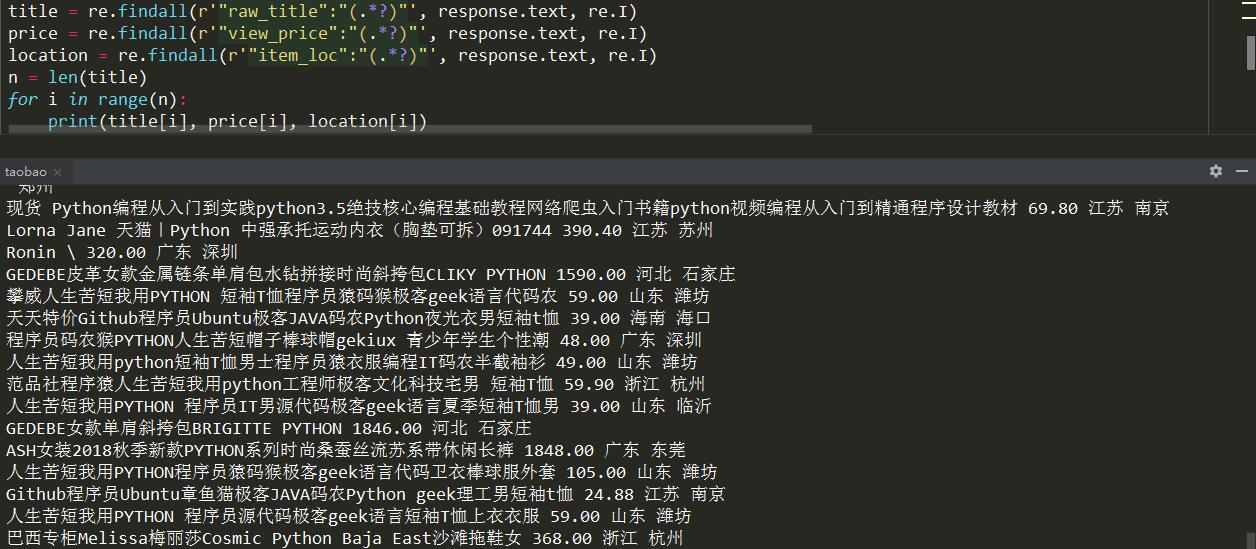
整理信息
获取到了宝贝信息之后我们就可以把它们存入文件或者数据库了。这里我们先把它们存入文件。
1 | file = open('taobao.txt', 'a', encoding='utf-8') |

完整代码
1 | import requests |